DPC機能評価係数×因子分析
仮説
- 機能評価係数Ⅱの各係数を決める因子を探索してみて、病院をクラスタリングすることができれば、病院機能を新しい視点で評価することができるのではないか。
- そのための前段階として因子分析をしてみる。
使用データ
機能評価係数Ⅱの内訳(医療機関別)令和4年4月1日時点 (https://www.mhlw.go.jp/content/12404000/000946859.pdf)
DPC機能評価係数Ⅱは、医療提供体制全体としての効率改善等へのインセンティブを評価した指標です。具体的には6つの係数(データ提出係数、効率性係数、複雑性係数、カバー率指数、救急医療係数、地域医療係数)によって構成されます。
機能評価係数Ⅱのうち、複雑性係数、カバー率指数、地域医療係数については、社会や地域の実情に応じて求められている機能の実現(地域における医療資源配分の最適化)という観点から 各医療 配分の最適化)という観点から、各医療機関群毎に評価設定されています。 (https://www.mhlw.go.jp/stf/shingi/2r9852000002d7vj-att/2r9852000002d886.pdf)
解析の流れ
平行分析をして抽出する因子数を推定
因子分析を実行
- 結果を表示
- 結果を図で表示
結果
1. 平行分析をして抽出する因子数を推定
以下のコードをRで実行する。
# ライブラリのインポート library(psych) # fa.parallel: 平行分析の実施(視覚的に適切な因子数を判断) # fm: 因子抽出法(minres 最小残差法、pa 主因子法、ml 最尤法) results.prl <- fa.parallel(df[, c(5:13), fm="ml"])

- 赤い点線を下回る因子や主成分を抽出しても意味がない。
- 上の図より因子数は4, 主成分数は3が推奨されている。
2. 因子分析を実行
1. 結果を表示.
以下のコードを実行する。
# ライブラリのインポート library(psych) # fa.parallel: 平行分析の実施(視覚的に適切な因子数を判断) # fm: 因子抽出法(minres 最小残差法、pa 主因子法、ml 最尤法) results.prl <- fa.parallel(df[, c(5:13), fm="ml"]) # FA(因子分析) # fa: 因子分析の実行 # fm: 因子抽出法(minres 最小残差法、pa 主因子法、ml 最尤法) # nfactors: 因子数(抽出したい軸の数) # rotate: 回転法(直行回転 varimax等、斜交回転 promax等) # scores: 因子得点算出法(回帰法 regression) resultFA <- fa(df[, (5:13)], nfactors = 4, fm = "ml", rotate = "varimax", scores = "regression") # 結果の表示 # digits: 小数点以下表示桁の指定 # sort=TRUEを指定(各項目ごとの因子負荷量がソートされる) print(resultFA, digits = 2, sort = TRUE)
2. 結果を図で表示
因子分析の結果を記述したものが以下。

結果の見方
テーブルの項目
- item: 変数のもとの順序
- ML1~4: 共通因子ごとの因子負荷量(各変数の寄与の度合い)
- h2: 共通性(各変数が共通因子で説明できる度合い)
- u2: 独自性(各変数が共通因子で説明できない度合い。大きい変数が多いと望ましくない)
- com: 複雑性(各変数の因子負荷量が複数の共通因子にまたがっている度合い)
- 表示された結果を上から準に眺めていき、どの共通因子への因子負荷量が高いかで変数を分ける(上の例では4つ)
- 上左から順に見ていき、ML1とML2の絶対値が逆転するところが主にML1に寄与する項目とML2に寄与する項目の境目。
- Cumultive var(累積寄与率) の値を見て、どれくらいの分散が説明できるかを確認する
- 上の例ではML3までで64%の分散を説明できる
図示したものは以下。

議論
結果の解釈
- ML1は定量評価係数(小児)と定量評価係数(小児以外)と地域医療係数が主な変数
- → 地域医療貢献度(どれだけ地域医療を頑張っているか)
- ML2は体制評価係数とカバー係数が主な変数
- → 疾患対応度(どれだけ5疾病5事業の疾患を見ていて、かつ診療できる疾患の幅があるか)
- ML4は効率性係数(+)と複雑性係数(-)が主な変数
- → 総合的入院期間指数 or 総合的重症度(どれだけ入院期間が短く、医療資源投入量が少なくてすむ患者を見ているか)
- この指数が高い方が入院期間が短い
- → 総合的入院期間指数 or 総合的重症度(どれだけ入院期間が短く、医療資源投入量が少なくてすむ患者を見ているか)
- ML3はあまりいい評価指標とはならなそう
限界点
- 結果の解釈には個人的な解釈が含まれてしまう。DPC機能評価係数Ⅱに対する知識が足りないため、議論で挙げた解釈(地域医療貢献度、疾患対応度、総合的入院期間指数・総合的重症度)が正しくない可能性がある。
- DPC機能評価係数Ⅱ自体が、病院機能を総合的に捉えるための指標であるため、因子分析する必要性が高くない。
参考サイト
- 機能評価係数Ⅱの内訳(医療機関別)令和4年4月1日時点 (https://www.mhlw.go.jp/content/12404000/000946859.pdf)
- DPC/PDPSの機能評価係数Ⅱについて (https://www.mhlw.go.jp/stf/shingi/2r9852000002d7vj-att/2r9852000002d886.pdf)
二次医療圏別 循環器疾患 患者数予測
仮説
- 二次医療圏ごとに循環器疾患の患者数を予測できれば面白そう(+年齢別もできたら)
- ex) A医療圏の40-44歳では1 年間に〜人くらい患者が発生する
- 価値
- 医療資源:治療薬、医療費の予測可能
- 予防:患者数の目安としてこの値を目標に予防施策
- 地域間比較:都道府県内の医療圏ごとに比較できる
使用データ
- 第7回NDBオープンデータ(特定健診:2019年・平成31年(令和元年))(https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177221_00011.html)
- 収縮期血圧 二次医療圏別
- LDLコレステロール 二次医療圏別
- BMI 二次医療圏別
- 腹囲 二次医療圏別
- 空腹時血糖 二次医療圏別
- HDLコレステロール 二次医療圏別
- HbA1c 二次医療圏別
- 患者調査 平成29年患者調査 下巻(都道府県・二次医療圏) (https://www.e-stat.go.jp/dbview?sid=0003313914)
データ詳細
第7回オープンデータでは特定健診のデータを用いました。項目としては、主に虚血性心疾患など循環器疾患発症のリスクファクターとなる項目を選んでいます。
<対応>
患者調査は疾患やサービス利用など別に、二次医療圏ごとの患者数が記載されています。
解析の流れ
結果
1. データ整形
データ整形のブログを2本投稿していますので、興味のある方は参考にしてください。
NDBオープンデータ(二次医療圏別収縮期血圧)のクリーニング - Path to でーたさいえんてぃすと
NDBオープンデータ(二次医療圏別LDLコレステロール)のクリーニング - Path to でーたさいえんてぃすと
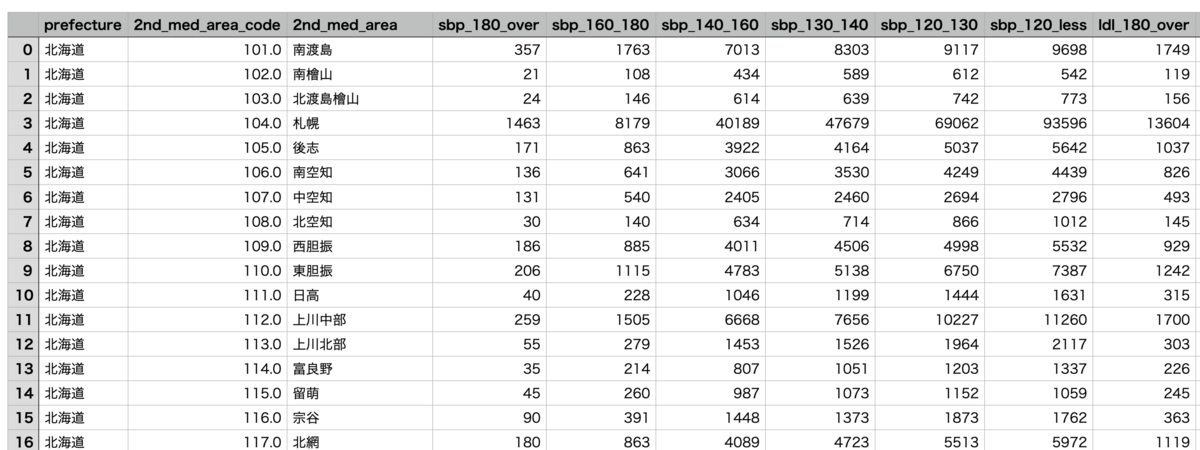
最終的なデータは以下のようになりました。二次医療圏をindexとして、収縮期血圧180以上の人数など説明変数が1列ごとに並んでいます。
2, 3. 機械学習モデルを作成、モデルを評価
様々な回帰分析の機械学習モデルを作成しましたが、精度が一番高かったのはRandom Forrestでした。 ここでは簡単に、パラメータ、訓練データとテストデータにおけるスコア、Scatter plotと残差プロット、学習曲線を載せます。
- パラメータ
〜 # rfr_modelがRandom Forrestのモデル rfr_model.get_params() """ {'bootstrap': True, 'ccp_alpha': 0.0, 'criterion': 'squared_error', 'max_depth': None, 'max_features': 1.0, 'max_leaf_nodes': None, 'max_samples': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'n_estimators': 100, 'n_jobs': None, 'oob_score': False, 'random_state': 42, 'verbose': 0, 'warm_start': False} """ 〜
- 訓練データとテストデータにおけるスコア
〜 """ 訓練データ MAE = 78.40996168582376 MSE = 23704.877394636016 RMSE = 153.96388340983094 R2_score = 0.9624347539252985 テストデータ MAE = 167.72727272727272 MSE = 60214.78787878788 RMSE = 245.387016524485 R2_score = 0.6328654386652484 """ 〜
Scatter Plot
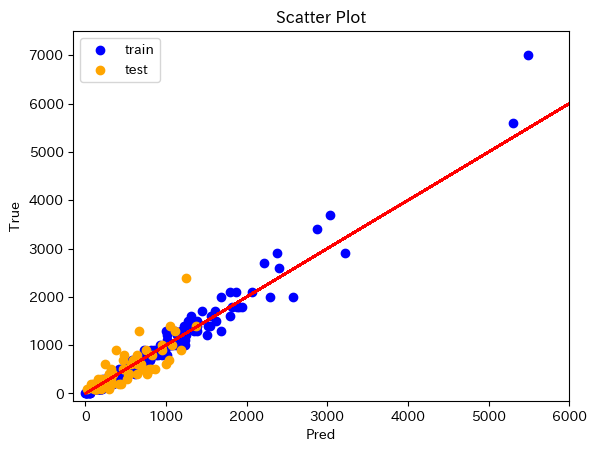
図2 Scatter Plot 残差プロット
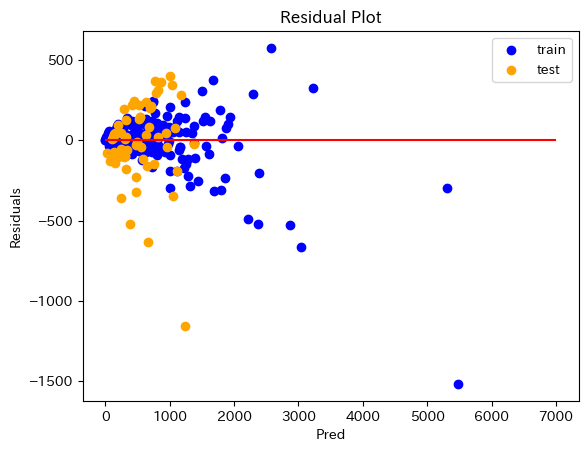
図3 残差プロット 学習曲線
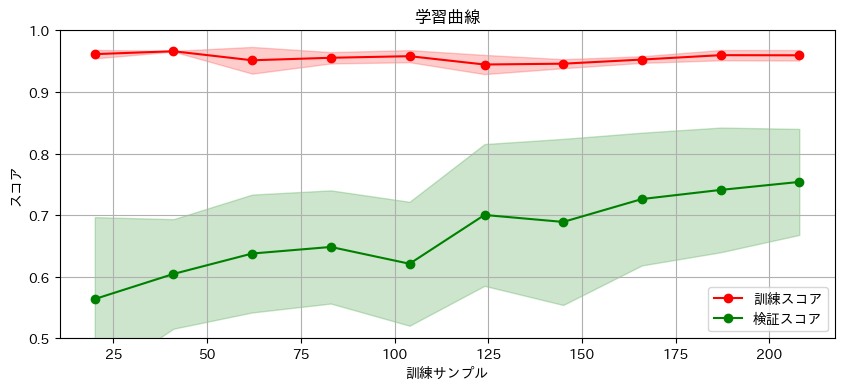
図4 Random Forrestの学習における学習曲線
4. 精度向上
今回はモデルの精度向上のため、2つの方法を試してみました。 結論から言うと、どちらの方法でも精度は向上しませんでした…。
- グリッドサーチ
グリッドサーチ後のスコアは以下です。
〜 """ MAE = 170.0138478945297 MSE = 60469.04156268217 RMSE = 245.904537499173 R2_score = 0.6313152328438448 """ 〜
- 特徴選択
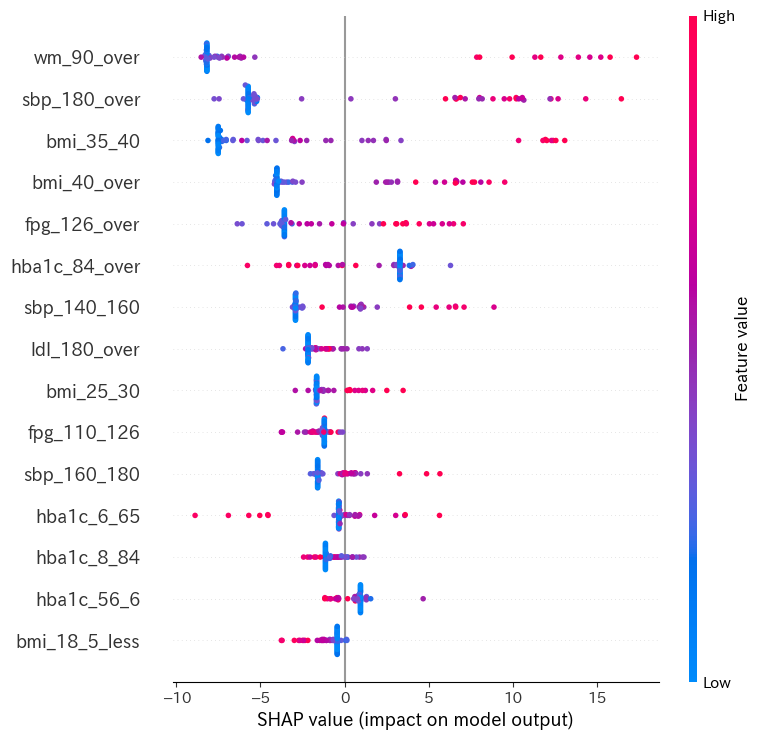
今回はEmbedded Methodとして、SHAP値を計算し、説明変数(特徴量)の数を絞ってみました。 SHAPは学習済みのモデルにおいて、各説明変数が予測値にどのような影響を与えたかを貢献度として定義して算出するモデルのことです。 つまり、今回は循環器疾患の予測において、重要な貢献をした説明変数を定量的に表すのがSHAPです。 このSHAPを行い、貢献度が高い説明変数だけを残してモデルを再学習させることで、データのノイズを減らして精度向上を試みました。 SHAP値は以下のような結果となりました。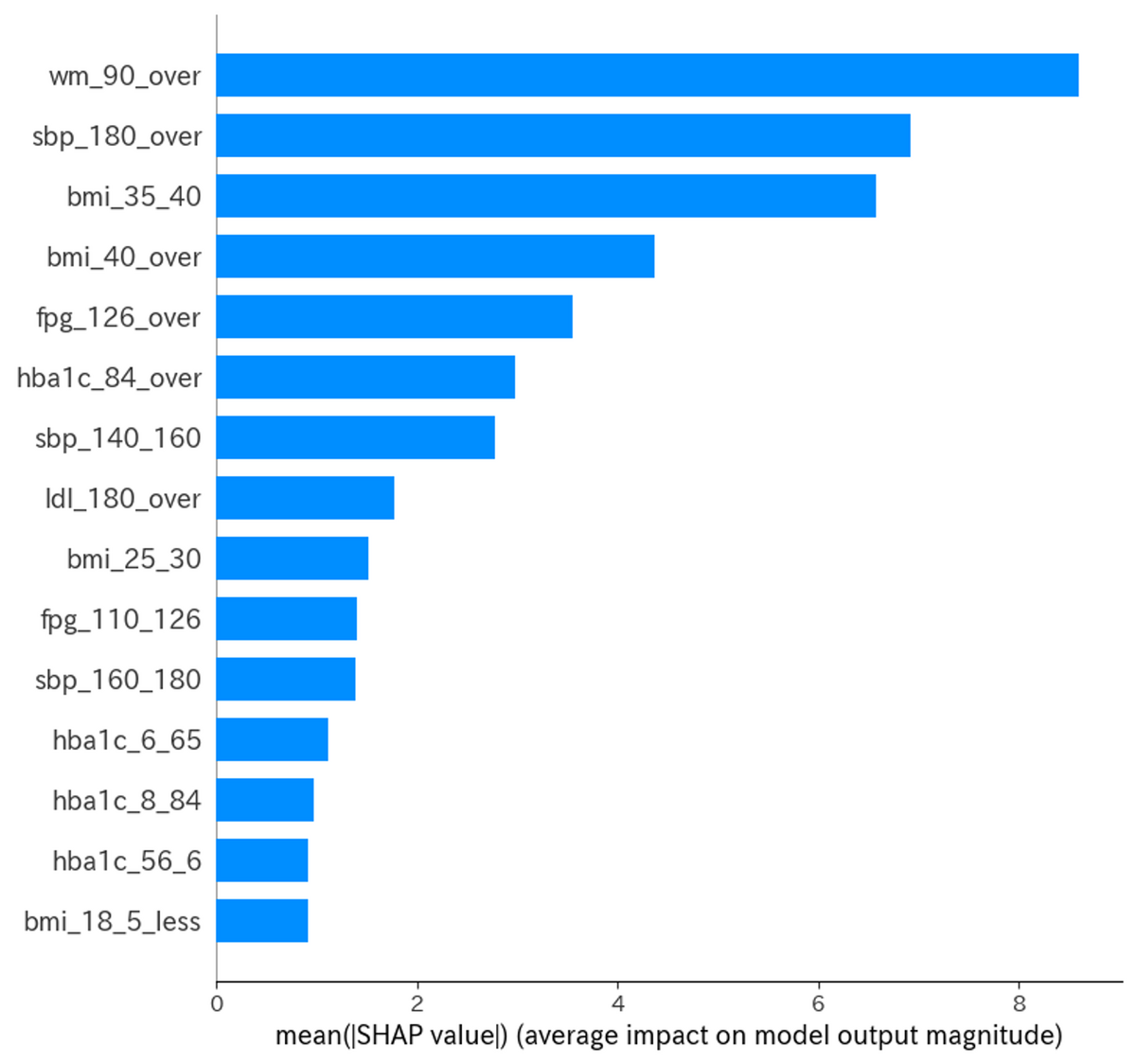
図5 SHAP値
このグラフは各説明変数の目的変数に対する貢献度合いを青〜赤で表示したものです。
例を上げると、最も貢献度が高いwm_90_over(腹囲90cm以上)ではSHAPが大きいと赤い点が多くなっています。これは、二次医療圏における腹囲90cm以上の人が多いと、循環器疾患の患者数も多くなることを示しています。つまり、SHAPが大きい範囲で赤が多いことは目的変数が大きくなる方向への貢献を表しています。
以上より、説明変数を大幅に減らして、5つの説明変数でモデルを学習させてみました。結果は以下です。
〜 """ 訓練データ スコア MAE = 10.39463601532567 MSE = 822.6321839080459 RMSE = 28.68156522765182 R2_score = 0.9142381209635456 テストデータ スコア MAE = 17.12121212121212 MSE = 1103.7878787878788 RMSE = 33.22330324919361 R2_score = 0.463979933110368 """ 〜
議論
今回の分析では、主にR2スコアを精度の指標としています。 結果より、Random Forrestによって訓練データに対しては精度96%、テストデータに対しては精度63%で二次医療圏の循環器疾患患者数を予測することができました。
Scatter Plotにおいて、赤のラインが正解、青の点が訓練データに対する予測、オレンジの点がテストデータに対する予測です。これを見ると、ある程度当てはまりの良い予測ができていると思います。 ただ、残差プロットでは点が散らばっており、理想的な予測ができているとは言えません…。
学習曲線を見ても、検証スコアが上がりきっておらず、データ数の不足が考えられます。
精度向上に関して、グリッドサーチを行い、最適なパラメータを探索して再度モデルを学習させてみましたが、元のモデルの精度63%を上回る事はできませんでした。
また、SHAP値を計算して貢献度の小さい説明変数を除外し、再度モデルを学習させてみましたが、精度は46%でもとのモデルの精度を上回る事はできませんでした。ただし、SHAP値を計算することで、循環器疾患の患者数予測に重要な貢献をする指標を探索することはできました。具体的には、腹囲90cm以上、収縮期血圧180以上、BMI35~40, BMI40以上、空腹時血糖126以上(上位5変数)が挙げられます。やはりメタボリックシンドロームや高血圧の人が多い二次医療圏ほど、循環器疾患の患者数が多い傾向にあることが分かりますね。
限界点
- モデルの過学習
- 訓練スコアは非常にいい精度が出ているのに対し、検証スコア及びテストデータに対するスコアの精度がいまいちであり、過学習が考えられます。
- データ数が少ないことが一番の原因と考えられるので、別年度のデータも使えばより精度向上が期待できるのではないかと思われます。
- 年齢、性に関して比較していない
- 今回の解析は40~74歳、男性のデータをすべて合計して、まとめて解析した結果です。
- 年齢区分別(ex 40~44歳男性など)、女性に関しても解析する必要があると思われます。
参考サイト
第7回NDBオープンデータ(https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177221_00011.html)
狭心症・心筋梗塞などの心臓病(虚血性心疾患) -eヘルスネット
(https://www.e-healthnet.mhlw.go.jp/information/metabolic/m-05-005.html#:~:text=%E8%99%9A%E8%A1%80%E6%80%A7%E5%BF%83%E7%96%BE%E6%82%A3%E3%81%AE%EF%BC%93%E5%A4%A7%E5%8D%B1%E9%99%BA%E5%9B%A0%E5%AD%90%E3%81%AF,%E8%A6%8B%E3%81%A4%E3%81%91%E3%82%8B%E3%81%93%E3%81%A8%E3%81%8C%E9%87%8D%E8%A6%81%E3%81%A7%E3%81%99%E3%80%82)
モデル構築・適用(https://qiita.com/tk-tatsuro/items/ec8c1a36582d4bec7924)
学習曲線(Learning Curve)で過学習、学習不足を検証(https://www.pep4.net/datascience/4498/)
NDBオープンデータ(二次医療圏別LDLコレステロール)のクリーニング
第7回NDBオープンデータのデータクリーニングを行ったソースコードを載せます。
今回の元データは 特定健診によって得られたデータである、LDLコレステロール 二次医療圏別製年齢階級別分布です。
元データは以下のようなエクセルファイルです。

データ解析しやすいように、LDLコレステロールのクラスは列に設定しました。
下のコードの年齢と性別の部分を変えれば、自由にエクセルファイルに出力が可能です。
例として、男性の全年齢階級合計(中計)の二次医療圏別性年齢階級LDLコレステロール分布をデータクリーニングしてみます。
〜 import numpy as np import pandas as pd # LDLコレステロールのデータ読み込み df_ldl = pd.read_excel("LDLchol_2ndmed_7ndb.xlsx") # titleを取得 df_ldl_title = df_ldl.columns[0] # 検査データの単位を取得 df_ldl_unit = df_ldl.iloc[0, 1] df_ldl = pd.read_excel("LDLchol_2ndmed_7ndb.xlsx", skiprows =3) # 列名の変更 df_ldl = df_ldl.drop(df_ldl.index[[0]]) df_ldl = df_ldl.rename(columns={"Unnamed: 0": "prefecture", "Unnamed: 1": "2nd_med_area_code", "Unnamed: 2": "2nd_med_area", "Unnamed: 3": "ldl_class" }) # 都道府県などの欠損値を穴埋め df_ldl = df_ldl.fillna(method="ffill") # 二次医療圏判別不可を除外 df_ldl = df_ldl[df_ldl.loc[:, "prefecture"] != "二次医療圏判別不可"] # 男性と女性のデータを区別 # 男性 rename_cols = ["40~44歳", "45~49歳", "50~54歳", "55~59歳", "60~64歳", "65~69歳", "70~74歳", '中計'] df_ldl = df_ldl.rename(columns={rename_col: f"{rename_col}_男性" for rename_col in rename_cols}) # 女性 rename_cols_women = [f"{i}.1" for i in rename_cols] df_ldl = df_ldl.rename(columns={rename_col_woman: rename_col_woman.replace(".1", "") for rename_col_woman in rename_cols_women}) df_ldl = df_ldl.rename(columns={rename_col: f"{rename_col}_女性" for rename_col in rename_cols}) # 今回は男性の中計のデータを抽出 df_ldl = df_ldl.loc[:, ["prefecture","2nd_med_area_code", "2nd_med_area", "ldl_class", "中計_男性"]] # 180overだけprefectureなどの列を残し、他のdfは血圧の列だけにして、後でmergeで結合 # 2nd_med_area_codeで結合しないと、同じ名前の二次医療圏があってdfの行数がおかしくなる # 180_over df_ldl_180_over = df_ldl[df_ldl.loc[:, "ldl_class"] == "180以上"].rename(columns={"中計_男性": "180以上"}).drop("ldl_class", axis=1) # 160-180 df_ldl_160_180 = df_ldl[df_ldl.loc[:, "ldl_class"] == "160以上180未満"].rename(columns={"中計_男性": "160以上180未満"}).drop(["prefecture","2nd_med_area", "ldl_class"], axis=1) # 140-160 df_ldl_140_160 = df_ldl[df_ldl.loc[:, "ldl_class"] == "140以上160未満"].rename(columns={"中計_男性": "140以上160未満"}).drop(["prefecture","2nd_med_area", "ldl_class"], axis=1) # 130-140 df_ldl_120_140 = df_ldl[df_ldl.loc[:, "ldl_class"] == "120以上140未満"].rename(columns={"中計_男性": "120以上140未満"}).drop(["prefecture","2nd_med_area", "ldl_class"], axis=1) # 120-130 df_ldl_100_120 = df_ldl[df_ldl.loc[:, "ldl_class"] == "100以上120未満"].rename(columns={"中計_男性": "100以上120未満"}).drop(["prefecture","2nd_med_area", "ldl_class"], axis=1) # 120_less df_ldl_100_less = df_ldl[df_ldl.loc[:, "ldl_class"] == "100未満"].rename(columns={"中計_男性": "100未満"}).drop(["prefecture","2nd_med_area", "ldl_class"], axis=1) # dfの結合 df_ldl = pd.merge(df_ldl_180_over, df_ldl_160_180, on = "2nd_med_area_code") df_ldl = pd.merge(df_ldl,df_ldl_140_160, on = "2nd_med_area_code") df_ldl = pd.merge(df_ldl,df_ldl_120_140, on = "2nd_med_area_code") df_ldl = pd.merge(df_ldl,df_ldl_100_120, on = "2nd_med_area_code") df_ldl = pd.merge(df_ldl,df_ldl_100_less, on = "2nd_med_area_code") # 列名の変更 df_ldl = df_ldl.rename(columns={"180以上": "ldl_180_over", "160以上180未満": "ldl_160_180", "140以上160未満": "ldl_140_160", "120以上140未満": "ldl_120_140", "100以上120未満": "ldl_100_120", "100未満": "ldl_100_less" }) # エクセルファイルに出力 df_ldl.to_excel("LDL_2ndmed_7ndb_total_m.xlsx") 〜
以上のコードを行うと、以下のように元のエクセルファイルを整形することができます。

参考サイト
第7回NDBオープンデータ
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177221_00011.html
NDBオープンデータ(二次医療圏別収縮期血圧)のクリーニング
第7回NDBオープンデータのデータクリーニングを行ったソースコードを載せます。
今回の元データは収縮期血圧 二次医療圏別性年齢階級別分布です。
元データは以下のようなエクセルファイルです。

データ解析しやすいように、血圧のクラスは列に設定しました。
下のコードの年齢と性別の部分を変えれば、自由にエクセルファイルに出力が可能です。
例として、40~44歳の男性の二次医療圏別性年齢階級収縮期血圧分布をデータクリーニングしてみます。
〜 import numpy as np import pandas as pd # 収縮期血圧のデータ読み込み df_sbp = pd.read_excel("SBP_2ndmed_7ndb.xlsx") # titleを取得 df_sbp_title = df_sbp.columns[0] # 検査データの単位を取得 bp_sbp_unit = df_sbp.iloc[0, 1] df_sbp = pd.read_excel("SBP_2ndmed_7ndb.xlsx", skiprows =3) # 列名の変更 df_sbp = df_sbp.drop(df_sbp.index[[0]]) df_sbp = df_sbp.rename(columns={"Unnamed: 0": "prefecture", "Unnamed: 1": "2nd_med_area_code", "Unnamed: 2": "2nd_med_area", "Unnamed: 3": "sbp_class" }) # 都道府県などの欠損値を穴埋め df_sbp = df_sbp.fillna(method="ffill") # 二次医療圏判別不可を除外 df_sbp = df_sbp[df_sbp.loc[:, "prefecture"] != "二次医療圏判別不可"] # 男性と女性のデータを区別 # 男性 rename_cols = ["40~44歳", "45~49歳", "50~54歳", "55~59歳", "60~64歳", "65~69歳", "70~74歳", '中計'] df_sbp = df_sbp.rename(columns={rename_col: f"{rename_col}_男性" for rename_col in rename_cols}) # 女性 rename_cols_women = [f"{i}.1" for i in rename_cols] df_sbp = df_sbp.rename(columns={rename_col_woman: rename_col_woman.replace(".1", "") for rename_col_woman in rename_cols_women}) df_sbp = df_sbp.rename(columns={rename_col: f"{rename_col}_女性" for rename_col in rename_cols}) # 今回は男性の40~44歳のデータを抽出 df_sbp = df_sbp.loc[:, ["prefecture","2nd_med_area_code", "2nd_med_area", "sbp_class", "40~44歳_男性"]] # 180overだけprefectureなどの列を残し、他のdfは血圧の列だけにして、後でmergeで結合 # 2nd_med_area_codeで結合しないと、同じ名前の二次医療圏があってdfの行数がおかしくなる # 180_over df_sbp_180_over = df_sbp[df_sbp.loc[:, "sbp_class"] == "180以上"].rename(columns={"40~44歳_男性": "180以上"}).drop("sbp_class", axis=1) # 160-180 df_sbp_160_180 = df_sbp[df_sbp.loc[:, "sbp_class"] == "160以上180未満"].rename(columns={"40~44歳_男性": "160以上180未満"}).drop(["prefecture","2nd_med_area", "sbp_class"], axis=1) # 140-160 df_sbp_140_160 = df_sbp[df_sbp.loc[:, "sbp_class"] == "140以上160未満"].rename(columns={"40~44歳_男性": "140以上160未満"}).drop(["prefecture","2nd_med_area", "sbp_class"], axis=1) # 130-140 df_sbp_130_140 = df_sbp[df_sbp.loc[:, "sbp_class"] == "130以上140未満"].rename(columns={"40~44歳_男性": "130以上140未満"}).drop(["prefecture","2nd_med_area", "sbp_class"], axis=1) # 120-130 df_sbp_120_130 = df_sbp[df_sbp.loc[:, "sbp_class"] == "120以上130未満"].rename(columns={"40~44歳_男性": "120以上130未満"}).drop(["prefecture","2nd_med_area", "sbp_class"], axis=1) # 120_less df_sbp_120_less = df_sbp[df_sbp.loc[:, "sbp_class"] == "120未満"].rename(columns={"40~44歳_男性": "120未満"}).drop(["prefecture","2nd_med_area", "sbp_class"], axis=1) # dfの結合 df_sbp = pd.merge(df_sbp_180_over, df_sbp_160_180, on = "2nd_med_area_code") df_sbp = pd.merge(df_sbp,df_sbp_140_160, on = "2nd_med_area_code") df_sbp = pd.merge(df_sbp,df_sbp_130_140, on = "2nd_med_area_code") df_sbp = pd.merge(df_sbp,df_sbp_120_130, on = "2nd_med_area_code") df_sbp = pd.merge(df_sbp,df_sbp_120_less, on = "2nd_med_area_code") # 列名の変更 df_sbp = df_sbp.rename(columns={"180以上": "180_over", "160以上180未満": "160_180", "140以上160未満": "140_160", "130以上140未満": "130_140", "120以上130未満": "120_130", "120未満": "120_less" }) # エクセルファイルに出力 df_sbp.to_excel("SBP_2ndmed_7ndb_40_44_m.xlsx") 〜
以上のコードを行うと、以下のように元のエクセルファイルを整形することができます。 個人的にはこちらのほうが解析しやすいので、今後機械学習などの説明変数として利用する際に利用していきたいと思います。

参考サイト
第7回NDBオープンデータ https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177221_00011.html
ラーメン消費量・店舗数 × 血圧
仮説
都道府県別ラーメン消費量と血圧などの生活習慣病に関する検診データに相関関係があるのではないか?
使用データ
- 都道府県別ラーメン消費量_2019(https://region-case.com/rank-r1-ramen/)
- 都道府県別ラーメン店店舗数_2020(https://todo-ran.com/t/kiji/11806)
- 収縮期血圧_都道府県別性年齢階級別分布(第7回NDBオープンデータ)
- 都道府県別人口_2021 (https://www.stat.go.jp/data/nihon/02.html)
データ詳細
-
消費量:令和元年(2019年)に、都道府県民1人が、1年間に外食で何杯のラーメン(中華そば)を食べているのかを掲載しています(1杯は醤油ラーメン)。今回のデータでは都道府県民1人あたりの支出金額(消費金額)を、主なラーメン消費量の解析対象としました。
-
店舗数:タウンページから「ラーメン店」として登録されている店舗数を都道府県別に集計したデータです。都道府県ごとに人口が違うので、各都道府県の人口で除して人口10万人あたりの店舗数を算出して解析しています。
-
収縮期血圧:NDBオープンデータに公開されている特定健診のデータです。都道府県ごとに、血圧180以上、160以上180未満、140以上160未満、130以上140未満、120以上130未満、120未満の人数が男女別に記載されています。これも各都道府県ごとの人口で除算し、人口10万人あたりの人数を算出して解析しています。
解析の流れ
結果
店舗数と消費量
各都道府県における人口10万人あたりの店舗数とラーメン消費量(上でも説明したように都道府県民1人あたりの支出金額(消費金額))をメインに説明していきます。
相関関係を確認
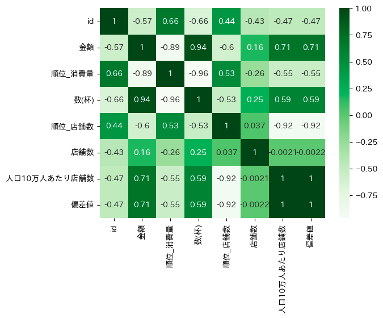
上の図は都道府県別ラーメン消費量のデータ_2019と都道府県別ラーメン店店舗数_2020のデータを元にした相関係数です。想像に難くないように、人口10万人あたり店舗数と金額には0.71という中程度〜強い正の相関が見られます。
線形回帰

こちらの図は人口10万人あたり店舗数とラーメン消費量(金額)の関係を表した散布図および線形回帰分析を行った結果を示した図です。相関関係からも予想できるように、やはり各都道府県における人口10万人あたりの店舗数が多いと、都道府県民一人あたりの消費金額も多くなるようです。ただし、線形回帰分析の決定係数は0.501とあまり精度が良くないことは否めません…。
都道府県別収縮期血圧人数と店舗数・消費量
都道府県別・収縮期血圧の範囲(血圧180以上、160以上180未満、140以上160未満、130以上140未満、120以上130未満、120未満)別人数と店舗数・消費量の関係を見ていきます。
今回は比較的大きな違いが見られた血圧140以上と血圧120未満の男性データで比較してみます。
血圧140以上
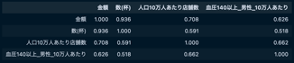
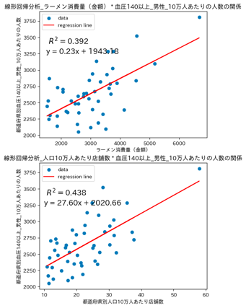
(都道府県別収縮期血圧人数と店舗数・消費量(血圧140以上))
都道府県別血圧140以上(高血圧)の人数とラーメン消費量(金額)の間の相関係数は0.626、都道府県別血圧140以上(高血圧)の人数と人口10万人あたり店舗数の間の相関係数は0.662でした。
血圧120未満

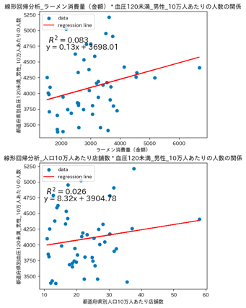
(都道府県別収縮期血圧人数と店舗数・消費量(血圧120未満))
都道府県別血圧120未満(正常血圧)の人数とラーメン消費量(金額)の間の相関係数は0.288、都道府県別血圧120未満(正常血圧)の人数と人口10万人あたり店舗数の間の相関係数は0.162でした。
以上の結果をまとめると、
- 都道府県別ラーメンデータとして、店舗数と消費量(金額)に相関関係あり(0.71など)
- 都道府県別収縮期血圧人数と店舗数・消費量(男性/女性)に相関関係あり
- 金額:0.626
- 人口10万人あたり店舗数:0.662
- 血圧140以上 vs 血圧120未満で比較すると、血圧140以上の方が相関が強い
- 血圧140以上 vs 血圧120未満
- 金額:0.626 vs 0.288
- 人口10万人あたり店舗数:0.662 vs 0.162
- 回帰直線の傾きを見るに、線形回帰の係数も大きい
- 血圧140以上 vs 血圧120未満
のような結果になりました。
議論
以下に結果から推察されることを挙げてみます。
- ラーメン消費量(金額)と人口10万人あたり店舗数が多いと、人口10万人あたり高血圧患者数も多いという相関関係がある
つまり、ラーメンの食べすぎが原因で高血圧患者が多いという可能性より、高塩分の食事を好む人達が多い都道府県では、当然高血圧患者も多いという可能性の方が高いと思われます。ただ、血圧140以上の人数と血圧120未満の人数を比較した際、明らかに相関係数の値が異なる(血圧140以上の人数の方が相関係数が大きい)という結果を定量化できたのは意味があることだと考えています。
限界点
以下に、今回の解析での限界点や不備について列挙します…。
- データの年が揃えられていない
- 人口10万人あたりを算出するとき、男女別に除算していない
- 線形回帰の精度が良くない
- 1杯あたりのラーメンの金額が考慮されていない
- 例えば、1杯あたりのラーメンの値段が高い都道府県では、消費量が少なくても金額が高くなる可能性がある
以上です。
この前、ラーメン消費量第一位は何県、みたいなニュースをたまたま見たので、血圧とは関連あるのかなと思い、解析してみました。
他にもオープンデータはたくさんあるので、色々解析してみたいと思います。
参考サイト
https://region-case.com/rank-r1-ramen/
https://todo-ran.com/t/kiji/11806
第7回NDBオープンデータ(https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177221_00011.html)
https://www.stat.go.jp/data/nihon/02.html