二次医療圏別 循環器疾患 患者数予測
仮説
- 二次医療圏ごとに循環器疾患の患者数を予測できれば面白そう(+年齢別もできたら)
- ex) A医療圏の40-44歳では1 年間に〜人くらい患者が発生する
- 価値
- 医療資源:治療薬、医療費の予測可能
- 予防:患者数の目安としてこの値を目標に予防施策
- 地域間比較:都道府県内の医療圏ごとに比較できる
使用データ
- 第7回NDBオープンデータ(特定健診:2019年・平成31年(令和元年))(https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177221_00011.html)
- 収縮期血圧 二次医療圏別
- LDLコレステロール 二次医療圏別
- BMI 二次医療圏別
- 腹囲 二次医療圏別
- 空腹時血糖 二次医療圏別
- HDLコレステロール 二次医療圏別
- HbA1c 二次医療圏別
- 患者調査 平成29年患者調査 下巻(都道府県・二次医療圏) (https://www.e-stat.go.jp/dbview?sid=0003313914)
データ詳細
第7回オープンデータでは特定健診のデータを用いました。項目としては、主に虚血性心疾患など循環器疾患発症のリスクファクターとなる項目を選んでいます。
<対応>
患者調査は疾患やサービス利用など別に、二次医療圏ごとの患者数が記載されています。
解析の流れ
結果
1. データ整形
データ整形のブログを2本投稿していますので、興味のある方は参考にしてください。
NDBオープンデータ(二次医療圏別収縮期血圧)のクリーニング - Path to でーたさいえんてぃすと
NDBオープンデータ(二次医療圏別LDLコレステロール)のクリーニング - Path to でーたさいえんてぃすと
最終的なデータは以下のようになりました。二次医療圏をindexとして、収縮期血圧180以上の人数など説明変数が1列ごとに並んでいます。
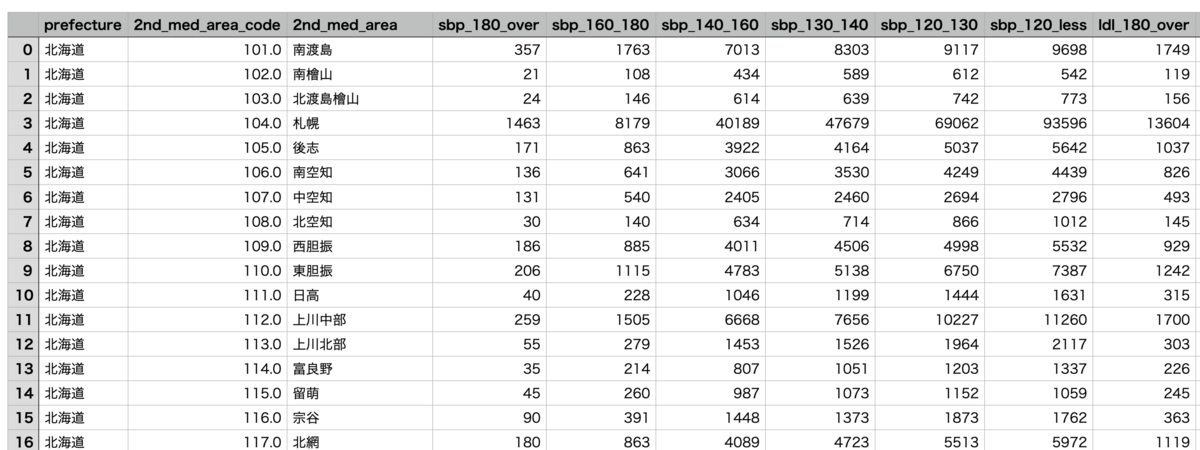
2, 3. 機械学習モデルを作成、モデルを評価
様々な回帰分析の機械学習モデルを作成しましたが、精度が一番高かったのはRandom Forrestでした。 ここでは簡単に、パラメータ、訓練データとテストデータにおけるスコア、Scatter plotと残差プロット、学習曲線を載せます。
- パラメータ
〜 # rfr_modelがRandom Forrestのモデル rfr_model.get_params() """ {'bootstrap': True, 'ccp_alpha': 0.0, 'criterion': 'squared_error', 'max_depth': None, 'max_features': 1.0, 'max_leaf_nodes': None, 'max_samples': None, 'min_impurity_decrease': 0.0, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'n_estimators': 100, 'n_jobs': None, 'oob_score': False, 'random_state': 42, 'verbose': 0, 'warm_start': False} """ 〜
- 訓練データとテストデータにおけるスコア
〜 """ 訓練データ MAE = 78.40996168582376 MSE = 23704.877394636016 RMSE = 153.96388340983094 R2_score = 0.9624347539252985 テストデータ MAE = 167.72727272727272 MSE = 60214.78787878788 RMSE = 245.387016524485 R2_score = 0.6328654386652484 """ 〜
Scatter Plot
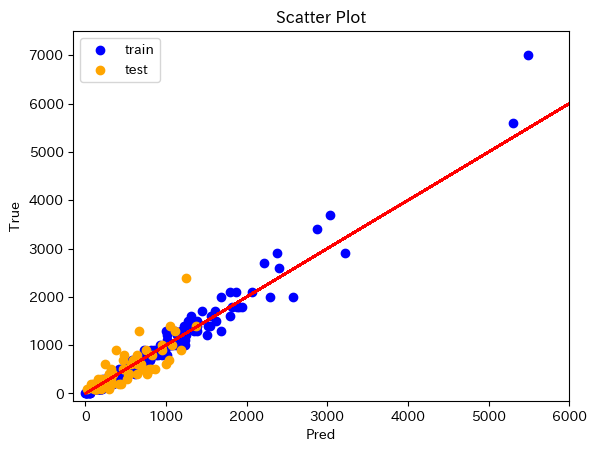
図2 Scatter Plot 残差プロット
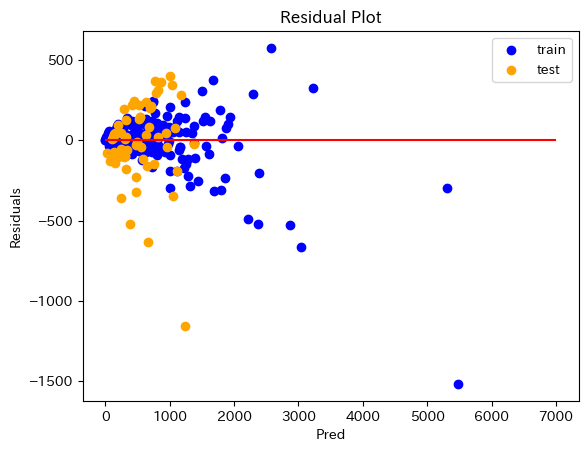
図3 残差プロット 学習曲線
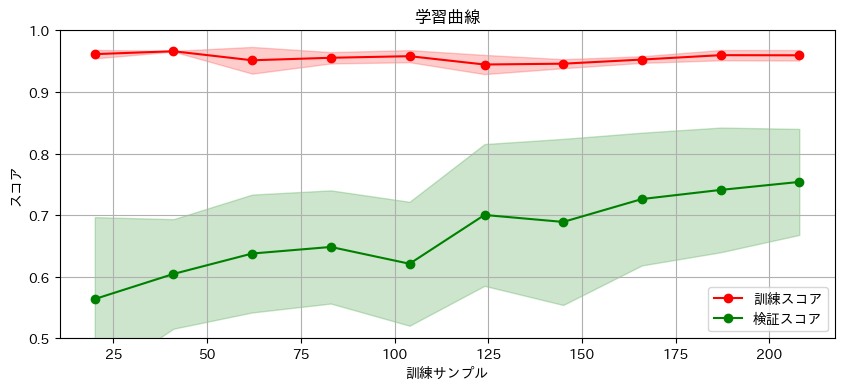
図4 Random Forrestの学習における学習曲線
4. 精度向上
今回はモデルの精度向上のため、2つの方法を試してみました。 結論から言うと、どちらの方法でも精度は向上しませんでした…。
- グリッドサーチ
グリッドサーチ後のスコアは以下です。
〜 """ MAE = 170.0138478945297 MSE = 60469.04156268217 RMSE = 245.904537499173 R2_score = 0.6313152328438448 """ 〜
- 特徴選択
今回はEmbedded Methodとして、SHAP値を計算し、説明変数(特徴量)の数を絞ってみました。 SHAPは学習済みのモデルにおいて、各説明変数が予測値にどのような影響を与えたかを貢献度として定義して算出するモデルのことです。 つまり、今回は循環器疾患の予測において、重要な貢献をした説明変数を定量的に表すのがSHAPです。 このSHAPを行い、貢献度が高い説明変数だけを残してモデルを再学習させることで、データのノイズを減らして精度向上を試みました。 SHAP値は以下のような結果となりました。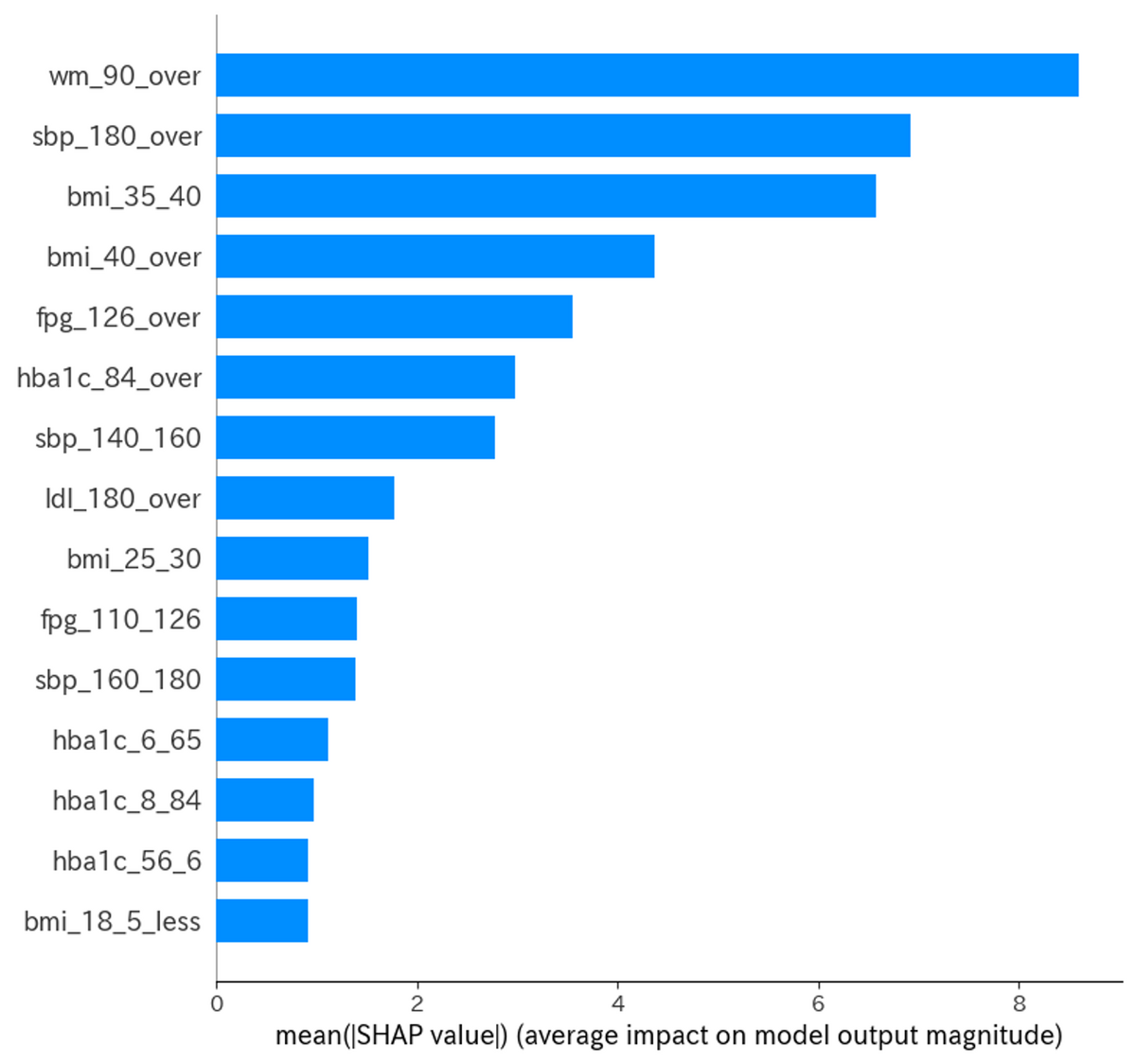
図5 SHAP値
このグラフは各説明変数の目的変数に対する貢献度合いを青〜赤で表示したものです。
例を上げると、最も貢献度が高いwm_90_over(腹囲90cm以上)ではSHAPが大きいと赤い点が多くなっています。これは、二次医療圏における腹囲90cm以上の人が多いと、循環器疾患の患者数も多くなることを示しています。つまり、SHAPが大きい範囲で赤が多いことは目的変数が大きくなる方向への貢献を表しています。
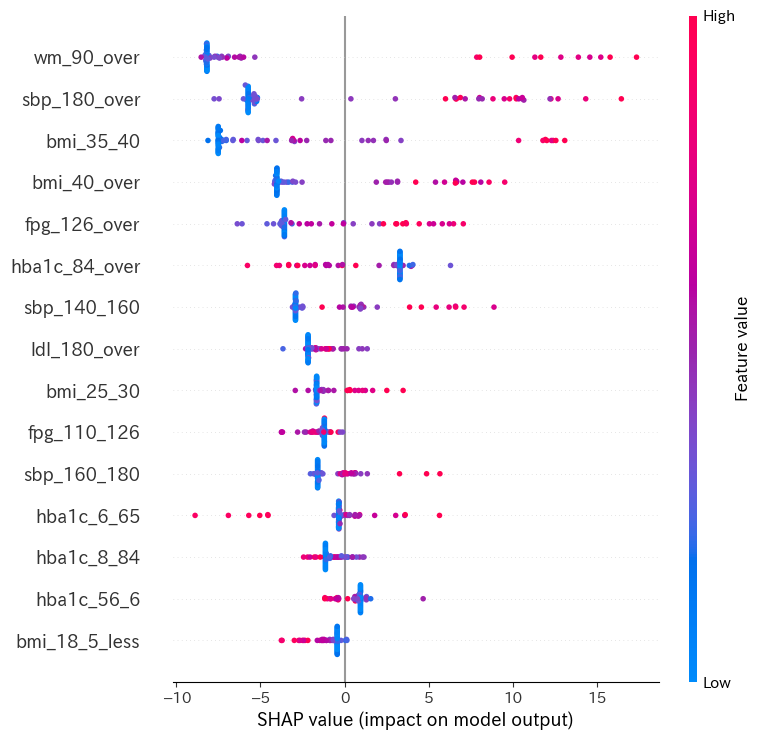
以上より、説明変数を大幅に減らして、5つの説明変数でモデルを学習させてみました。結果は以下です。
〜 """ 訓練データ スコア MAE = 10.39463601532567 MSE = 822.6321839080459 RMSE = 28.68156522765182 R2_score = 0.9142381209635456 テストデータ スコア MAE = 17.12121212121212 MSE = 1103.7878787878788 RMSE = 33.22330324919361 R2_score = 0.463979933110368 """ 〜
議論
今回の分析では、主にR2スコアを精度の指標としています。 結果より、Random Forrestによって訓練データに対しては精度96%、テストデータに対しては精度63%で二次医療圏の循環器疾患患者数を予測することができました。
Scatter Plotにおいて、赤のラインが正解、青の点が訓練データに対する予測、オレンジの点がテストデータに対する予測です。これを見ると、ある程度当てはまりの良い予測ができていると思います。 ただ、残差プロットでは点が散らばっており、理想的な予測ができているとは言えません…。
学習曲線を見ても、検証スコアが上がりきっておらず、データ数の不足が考えられます。
精度向上に関して、グリッドサーチを行い、最適なパラメータを探索して再度モデルを学習させてみましたが、元のモデルの精度63%を上回る事はできませんでした。
また、SHAP値を計算して貢献度の小さい説明変数を除外し、再度モデルを学習させてみましたが、精度は46%でもとのモデルの精度を上回る事はできませんでした。ただし、SHAP値を計算することで、循環器疾患の患者数予測に重要な貢献をする指標を探索することはできました。具体的には、腹囲90cm以上、収縮期血圧180以上、BMI35~40, BMI40以上、空腹時血糖126以上(上位5変数)が挙げられます。やはりメタボリックシンドロームや高血圧の人が多い二次医療圏ほど、循環器疾患の患者数が多い傾向にあることが分かりますね。
限界点
- モデルの過学習
- 訓練スコアは非常にいい精度が出ているのに対し、検証スコア及びテストデータに対するスコアの精度がいまいちであり、過学習が考えられます。
- データ数が少ないことが一番の原因と考えられるので、別年度のデータも使えばより精度向上が期待できるのではないかと思われます。
- 年齢、性に関して比較していない
- 今回の解析は40~74歳、男性のデータをすべて合計して、まとめて解析した結果です。
- 年齢区分別(ex 40~44歳男性など)、女性に関しても解析する必要があると思われます。
参考サイト
第7回NDBオープンデータ(https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000177221_00011.html)
狭心症・心筋梗塞などの心臓病(虚血性心疾患) -eヘルスネット
(https://www.e-healthnet.mhlw.go.jp/information/metabolic/m-05-005.html#:~:text=%E8%99%9A%E8%A1%80%E6%80%A7%E5%BF%83%E7%96%BE%E6%82%A3%E3%81%AE%EF%BC%93%E5%A4%A7%E5%8D%B1%E9%99%BA%E5%9B%A0%E5%AD%90%E3%81%AF,%E8%A6%8B%E3%81%A4%E3%81%91%E3%82%8B%E3%81%93%E3%81%A8%E3%81%8C%E9%87%8D%E8%A6%81%E3%81%A7%E3%81%99%E3%80%82)
モデル構築・適用(https://qiita.com/tk-tatsuro/items/ec8c1a36582d4bec7924)
学習曲線(Learning Curve)で過学習、学習不足を検証(https://www.pep4.net/datascience/4498/)